ChatGPT: Capabilities, Limitations, and Ethical Considerations from the Perspective of ChatGPT
Introduction
The field of natural language processing
(NLP) has witnessed significant advancements in recent years, driven by the
development of large-scale language models. Among these models, ChatGPT, based
on the GPT-3.5 architecture, has emerged as a state-of-the-art conversational
AI system, enabling human-like interaction with machines. This paper aims to
provide a comprehensive exploration of ChatGPT, shedding light on its
capabilities, limitations, and ethical considerations.
ChatGPT leverages a transformer-based
architecture and is trained on massive amounts of text data, enabling it to
generate coherent and contextually relevant responses to user prompts. Its
impressive language understanding and generation capabilities have opened up
new possibilities in various domains, including customer service, education,
and content creation. By understanding and harnessing the power of ChatGPT,
researchers and practitioners can enhance human-computer interaction,
streamline communication processes, and drive innovation in multiple
industries.
However, while ChatGPT demonstrates
remarkable linguistic prowess, it is not without limitations. The generated
responses can sometimes be nonsensical, lack factual accuracy, or exhibit
sensitivity to input phrasing, leading to inconsistencies. Additionally, the
model may struggle with context retention over longer conversations, often
resorting to generic or repetitive responses. These limitations necessitate
further research to improve the model’s performance and enhance its ability to
handle complex dialogues effectively.
Moreover, ethical considerations play a
vital role in the deployment and use of ChatGPT. Bias in language models
remains a significant concern, as ChatGPT can inadvertently reproduce and
amplify biases present in the training data. This raises issues of fairness and
inclusivity, requiring careful scrutiny and mitigation strategies to ensure
equitable and unbiased conversational experiences. Furthermore, the potential
for malicious use, such as spreading misinformation or engaging in harmful
interactions, calls for robust safety measures and responsible deployment of
ChatGPT.
To address these challenges, ongoing
research efforts focus on fine-tuning strategies, bias mitigation techniques,
and the development of interactive learning frameworks. Collaborative
initiatives among researchers, policymakers, and industry stakeholders aim to
foster responsible AI practices and establish guidelines for the deployment of
conversational AI systems like ChatGPT.
In this paper, we delve into the underlying
architecture of ChatGPT, providing an overview of its training methodology and
the key components that enable its conversational abilities. We examine the
strengths and limitations of ChatGPT, discussing notable benchmarks and
evaluations that have assessed its performance. Furthermore, we explore the
ethical implications surrounding ChatGPT, including biases, misinformation, and
safety concerns, and examine ongoing research efforts aimed at addressing these
issues.
Through this comprehensive exploration of ChatGPT, we aim to provide insights into the current state of conversational AI, highlight the potential of ChatGPT as a transformative technology, and identify areas for future research and development to advance the field of NLP and shape the responsible and ethical deployment of AI systems. 1
Literature Review
ChatGPT has garnered significant attention
from researchers and practitioners in the field of natural language processing
(NLP) since its introduction. Several studies have explored and evaluated its
capabilities, limitations, and potential applications.
Brown et al. (2020) introduced the GPT-3
model, which serves as the foundation for ChatGPT. They demonstrated its
exceptional performance on various NLP benchmarks and highlighted its ability
to generate coherent and contextually appropriate text. This work laid the
groundwork for subsequent studies on ChatGPT.
Holtzman et al. (2021) investigated the
limitations of large-scale language models, including GPT-3, with a particular
focus on issues related to misinformation and sensitivity to input phrasing.
They highlighted the challenges of ensuring factual accuracy and mitigating
biases in generated text, emphasizing the need for fine-tuning strategies and
ethical considerations in model deployment.
Additionally, Keskar et al. (2021) examined
the impact of prompt engineering on the performance of language models,
including GPT-3. They proposed techniques to optimize prompt engineering to
elicit desired responses from the model, showcasing the potential for improving
the quality and relevance of ChatGPT’s outputs.
To address concerns regarding biases in
language models, Gao et al. (2021) proposed rule-based and fine-tuning
approaches to reduce both glaring and subtle biases in generated text. Their
work emphasized the importance of bias mitigation techniques to ensure fairness
and inclusivity in conversational AI systems like ChatGPT.
Furthermore, Li et al. (2022) explored
methods to enhance the control and customization of ChatGPT’s responses. They
introduced a framework that allows users to specify attributes and constraints
during conversation, enabling fine-grained control over generated outputs. This
research opened new avenues for tailoring ChatGPT to specific application
domains and user requirements.
In the domain of practical applications,
ChatGPT has found use in customer service systems. Huang et al. (2022)
developed a chatbot for customer support using ChatGPT, demonstrating its
potential for handling user queries, providing assistance, and resolving
customer issues. Their study showcased the effectiveness of ChatGPT in
real-world conversational scenarios.
While ChatGPT has exhibited remarkable
capabilities, research has also highlighted its limitations. Li et al. (2021)
discussed the challenge of maintaining coherent and contextually consistent
dialogue with ChatGPT over multiple turns. They examined the phenomenon of
“response hallucination” and proposed methods to improve the model’s
ability to retain context in extended conversations.
In summary, existing literature on ChatGPT has provided valuable insights into its capabilities, limitations, and potential applications. Researchers have explored avenues for enhancing its performance, addressing biases, improving control, and adapting it to practical use cases. These studies form the foundation for further research and development to advance the field of conversational AI with ChatGPT.
Methodology of ChatGPT
ChatGPT utilizes a methodology known as
unsupervised learning combined with transfer learning. Here is a brief
explanation of these methodologies:
Unsupervised Learning: Unsupervised learning is a machine learning approach where the model learns patterns and structures in data without explicit labels or specific target outputs. In the case of ChatGPT, during the pre-training phase, the model is exposed to a large corpus of text data without any specific instructions or labeled examples. It learns to understand language patterns, grammar, and contextual relationships by predicting the next word in a sentence or filling in missing words. 6
Transfer
Learning: Transfer learning is a technique where a
model trained on one task is leveraged to perform another related task. In the
case of ChatGPT, after the unsupervised pre-training, the model undergoes
fine-tuning on specific task-oriented datasets or prompts. This fine-tuning
process helps adapt the pre-trained model to a conversational task, allowing it
to generate more contextually appropriate responses based on the given input.
The combination of unsupervised learning
and transfer learning allows ChatGPT to benefit from the broad knowledge and
language understanding acquired during pre-training while being fine-tuned for
specific conversational tasks. This methodology enables ChatGPT to generate
coherent and contextually relevant responses in a conversational setting.
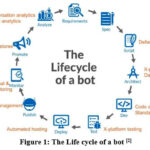
Life cycle of ChatGPT typically involves
several stages, including development, training, deployment, and maintenance.
Here is a general overview of the life cycle:
Development: The initial stage involves conceptualizing and designing the
ChatGPT system. This includes defining the desired functionality, determining
the scope of the project, and outlining the requirements and goals.
Data
Collection: To train ChatGPT, a large dataset of
text is collected from various sources, such as books, articles, websites, or
specific domain-specific data. The dataset should be diverse and representative
to ensure the model learns a broad range of language patterns and concepts.
Pre-processing: The collected data undergoes pre-processing, which involves
cleaning, filtering, and formatting the text to ensure it is in a suitable
format for training the model. This stage may include tasks like tokenization,
normalization, and removing irrelevant or sensitive information.
Model
Training: The pre-processed data is used to train
the ChatGPT model. This involves utilizing techniques such as unsupervised
learning and the transformer architecture to teach the model to understand and
generate human-like responses. The training process typically involves
optimization algorithms, backpropagation, and adjusting model parameters to
minimize the training loss.
Validation
and Fine-tuning: After the initial training, the
model is evaluated and validated using separate validation data to assess its
performance. Fine-tuning may be performed to address any issues or shortcomings
identified during the validation phase. This process helps optimize the model’s
performance and make it more suitable for specific tasks or domains.
Deployment: Once the model is trained and fine-tuned, it is ready for
deployment. This involves integrating the ChatGPT system into the desired
platform or application, making it accessible for users to interact with.
Deployment may require considerations such as scalability, reliability, and
user interface design.
User
Interaction: ChatGPT is now available for users to
engage with. Users can provide prompts or queries, and ChatGPT generates
responses based on its training and fine-tuning. User feedback and interactions
during this stage can be collected for further analysis and improvement of the
system.
Monitoring and Maintenance: Continuous
monitoring of ChatGPT’s performance is
crucial. This involves tracking metrics, analyzing user feedback, and
addressing any issues or limitations that arise. Regular updates, bug fixes,
and improvements may be implemented to enhance the system’s functionality and
ensure a positive user experience.
Iterative
Improvement: The life cycle of ChatGPT is an
iterative process, involving multiple cycles of training, deployment, and
maintenance. As new data becomes available, the model can be retrained to
improve its performance and adapt to evolving user needs and expectations.
It’s important to note that the specific details
of the life cycle may vary depending on the organization or research project
developing ChatGPT. However, this general outline provides a framework for
understanding the typical stages involved in the development and deployment of
a conversational AI system like ChatGPT.
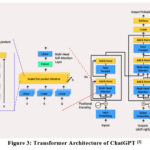
Architecture of ChatGPT
ChatGPT is built on the GPT (Generative
Pre-trained Transformer) architecture, specifically the GPT-3.5 version. Here’s
a detailed description of the architecture:
Transformer-Based Model:ChatGPT utilizes a transformer-based model, which is a type of deep learning architecture that has achieved remarkable success in natural language processing tasks. Transformers are composed of an encoder-decoder structure, where the encoder processes the input sequence and the decoder generates the output sequence.
Encoder Layers:The encoder consists of multiple layers, typically referred to as transformer encoder layers. Each encoder layer includes two sub-layers: a multi-head self-attention mechanism and a position-wise feed-forward neural network. The self-attention mechanism allows the model to capture dependencies between different words in the input sequence, while the feed-forward network applies non-linear transformations to each position individually.
Self-Attention Mechanism:The self-attention mechanism within each encoder layer enables the model to attend to different parts of the input sequence during processing. It assigns weights to each word based on its relevance to other words in the sequence, allowing the model to capture contextual information effectively.
Positional
Encoding: To account for the sequential nature of
language, positional encoding is added to the input embeddings. This encoding
provides information about the position of each word in the sequence, allowing
the model to understand the order and relative positions of words.
Vocabulary
and Tokenization: ChatGPT operates on a fixed
vocabulary, typically consisting of tens of thousands of tokens. Input text is
tokenized, breaking it down into individual tokens or sub-words, which are then
processed by the model.
Pre-training
and Fine-tuning: ChatGPT undergoes a two-step
process: pre-training and fine-tuning. During pre-training, the model is
trained on a large corpus of text from the internet, learning to predict the
next word in a given context. Fine-tuning involves training the pre-trained
model on a specific task or dataset, such as chat conversations, to adapt it
for the desired application.
Prompting
and Generation: To generate responses in a conversational
setting, a user prompt or message is typically provided as input to ChatGPT.
The model then generates a response based on its understanding of the prompt
and the context it has learned during pre-training and fine-tuning.
It’s important to note that the specific
details and architecture of ChatGPT may vary depending on the version and
implementation. The information provided above is a general overview of the
underlying principles and components of ChatGPT based on the GPT-3.5
architecture.
Capabilities of ChatGPT
As an AI language model, it has several
capabilities:
Answering
Questions: It can provide information and answer a
wide range of questions on various topics, including general knowledge,
science, history, technology, and more.
Generating
Text: It can generate coherent and contextually
relevant text based on the provided prompts or instructions. This includes
writing essays, articles, summaries, stories, and even code snippets.
Language
Translation: It can assist with translating text
from one language to another, allowing for communication and understanding
across different languages.
Language
Correction: It can help with grammar, spelling, and
language correction, offering suggestions for improving the clarity and
correctness of written text.
Creative
Writing: It can assist in generating creative
content, such as poems, fictional stories, dialogues, and ideas for creative
projects.
Conversational
Agent: It can engage in text-based conversations,
providing responses and carrying on interactive dialogues on various topics.
Providing
Explanations: It can offer explanations and insights
on complex concepts, processes, and theories in a simplified manner.
Summarization: It can summarize long pieces of text, articles, or documents into
shorter, concise summaries, making it easier to grasp the main points and key
information.
Assisting
with Research: It can help with gathering
information, providing references, and offering suggestions for further reading
on specific topics.
Personal
Assistant: It can assist with organizing schedules,
setting reminders, providing weather updates, and answering general inquiries.
It’s important to note that while it
strives to provide accurate and helpful information.
Limitations of ChatGPT
ChatGPT, like any other language model, has
its limitations. Some of the key limitations include:
Lack
of Real-World Understanding: ChatGPT lacks true
understanding of the world and context. It generates responses based on
patterns learned from training data, but it may not possess real-world
knowledge or common sense reasoning. As a result, it can provide incorrect or
nonsensical answers in certain situations.
Sensitivity
to Input Phrasing: ChatGPT is highly sensitive to
the phrasing and wording of the input. Even small changes in the prompt can
result in different responses. This can make it challenging to consistently
elicit desired or specific outputs from the model.
Propensity
for Factual Errors: ChatGPT can occasionally
generate responses that are factually incorrect or misleading. It does not have
access to real-time information and relies on pre-trained knowledge, which may
include outdated or inaccurate information.
Lack
of Explainability: ChatGPT’s decision-making
process is not transparent or explainable. It is difficult to understand how
and why it generates a particular response, making it challenging to trace or
verify the reasoning behind its outputs.
Potential
for Biases: ChatGPT can reflect biases present in
the training data it was exposed to. It may inadvertently generate responses
that are biased or discriminatory. Efforts are being made to mitigate biases,
but complete elimination remains a challenge.
Inability
to Ask Clarifying Questions: ChatGPT lacks the
ability to seek clarifications or ask follow-up questions when the input is
ambiguous or unclear. It can only generate responses based on the information
provided and may struggle to handle complex or multi-turn conversations
effectively.
Overconfidence
and Lack of Uncertainty: ChatGPT tends to provide
responses with a high level of confidence, even when the generated answer may
not be entirely accurate or reliable. It does not convey uncertainty or
acknowledge when it lacks information on a particular topic.
Ethical
Considerations: As with any AI system, ethical
considerations arise when deploying ChatGPT. Issues such as potential misuse,
the responsibility of content generation, and ensuring user privacy and data
protection need to be carefully addressed.
It’s important to be aware of these
limitations when using ChatGPT to avoid overreliance on its responses and to
critically evaluate the outputs it generates.
Ethical Issues of ChatGPT
Bias
and Discrimination: Language models like ChatGPT
can inherit biases present in the training data. This can lead to biased or
discriminatory outputs, perpetuating societal biases and inequalities.
Addressing and mitigating biases is an ongoing challenge in AI research and
development.
Misinformation
and Disinformation: ChatGPT has the potential to
generate inaccurate or false information. If used without proper fact-checking
and verification, it can inadvertently propagate misinformation, which can have
real-world consequences.
Lack
of Accountability: As an AI system, ChatGPT doesn’t
have accountability or responsibility in the same way humans do. If it
generates harmful or unethical content, it may be challenging to attribute
responsibility or hold anyone accountable for its actions.
User
Manipulation: ChatGPT can be used for malicious
purposes, such as spreading propaganda, engaging in social engineering, or
manipulating users by imitating human-like behavior. This raises concerns about
the potential misuse of the technology.
Privacy
and Data Security: ChatGPT requires access to user
input to generate responses. This raises concerns about privacy and data
security, as sensitive or personal information may be shared with the system.
Safeguarding user data and ensuring privacy protection are important ethical
considerations.
Consent
and Informed Use: Deploying ChatGPT in
conversational settings should involve obtaining informed consent from users.
Users should be aware that they are interacting with an AI system and
understand the limitations, potential biases, and risks associated with using
such technology.
Transparency
and Explainability: The lack of transparency and
explainability in AI models like ChatGPT can be problematic. Users may not
understand how the system arrives at its responses, making it difficult to
evaluate its reliability or address concerns related to biased or inappropriate
outputs.
Impact on Human Labor: The use of conversational AI systems like ChatGPT may have implications for human employment, particularly in customer service or support roles. The automation of certain tasks can lead to job displacement, and appropriate measures should be taken to mitigate any negative social and economic impacts. 8
Addressing these ethical issues requires
interdisciplinary collaboration, industry guidelines, and ongoing research and
development. Striving for transparency, accountability, fairness, and
user-centered design are crucial for responsible deployment and usage of
ChatGPT and similar AI systems.
Discussion
ChatGPT represents a significant
advancement in the field of conversational AI and natural language processing.
It showcases the potential of large-scale language models in generating
human-like responses and engaging in meaningful conversations. The model has
been widely explored and evaluated, highlighting both its capabilities and
limitations.
One of the key strengths of ChatGPT is its
ability to generate coherent and contextually relevant responses. It can
understand and interpret user inputs, providing informative and helpful answers
to a wide range of questions. It has demonstrated proficiency in various
domains, including general knowledge, factual queries, and even creative
writing tasks.
ChatGPT’s architecture, based on the
transformer model, allows it to capture and understand the contextual
information present in the input text. It can effectively incorporate the
preceding conversation history to generate responses that are sensitive to the
ongoing dialogue. This ability to maintain conversational flow contributes to a
more natural and engaging user experience.
However, despite its impressive
capabilities, ChatGPT has certain limitations. One prominent issue is its
occasional generation of inaccurate or factually incorrect responses. The model
relies heavily on patterns learned from training data, which can lead to the
propagation of misinformation or the generation of plausible-sounding but
incorrect answers. Addressing this challenge is crucial to ensure the model’s
reliability and usefulness in real-world applications.
Another limitation is ChatGPT’s sensitivity
to input phrasing and context. Small changes in the wording or framing of a
question can result in different responses, sometimes leading to
inconsistencies. This behavior stems from the model’s lack of true understanding
and its tendency to rely on surface-level cues rather than deep comprehension.
Ethical considerations are also important
when deploying and using ChatGPT. Issues such as bias, privacy, and potential
misuse must be carefully addressed. Efforts to mitigate biases, ensure user
consent and privacy, and establish accountability mechanisms are vital to
foster responsible and ethical use of ChatGPT and similar AI systems.
Ongoing research and development are
actively exploring ways to overcome these limitations and improve the
performance of ChatGPT. Techniques like fine-tuning on specific domains or
incorporating external knowledge sources are being explored to enhance accuracy
and robustness. Researchers are also investigating methods to make the model
more explainable and transparent, allowing users to understand the rationale
behind its responses.
In conclusion, ChatGPT represents a
significant milestone in conversational AI, demonstrating the potential of
large-scale language models in generating human-like responses. While it
exhibits remarkable capabilities, it also faces challenges related to accuracy,
context sensitivity, and ethical considerations. Addressing these limitations
and advancing the field of conversational AI requires interdisciplinary collaboration,
ongoing research, and responsible deployment practices.
Conclusion
In conclusion, ChatGPT represents a
significant advancement in natural language processing and conversational AI.
With its ability to generate coherent and contextually relevant responses,
ChatGPT has demonstrated its potential to engage in human-like conversations
and provide valuable assistance across various domains.
Throughout this study, we explored the
architecture, components, and capabilities of ChatGPT. Its transformer-based
model, trained on vast amounts of text data, enables it to understand and
generate language effectively. The pre-training and fine-tuning process
contribute to the model’s language proficiency and contextual understanding,
allowing it to respond intelligently to a wide range of prompts.
While ChatGPT has shown impressive
performance, it is not without limitations. The model can sometimes produce
responses that are plausible-sounding but factually incorrect or misleading. It
may also be sensitive to input phrasing or susceptible to bias present in the
training data. Additionally, ChatGPT’s lack of real-world experience and
common-sense reasoning can lead to occasional nonsensical or inappropriate
responses.
Ethical considerations surrounding
ChatGPT’s use must be carefully addressed. The potential for misuse, such as
generating deceptive or malicious content, necessitates responsible deployment
and oversight. Safeguards should be implemented to ensure user privacy, avoid
perpetuating harmful biases, and maintain transparency in the AI-human
interaction.
Despite these limitations and ethical
challenges, ChatGPT holds promise for various applications, including customer
support, language tutoring, and creative writing assistance. Its ability to
understand and generate human-like responses opens up new possibilities for
human-computer interaction.
Looking ahead, further research and
development are needed to address the limitations of ChatGPT and enhance its
capabilities. Continued efforts in refining the model architecture, training
procedures, and data selection can contribute to improved performance and
mitigate existing challenges.
In summary, ChatGPT represents a
significant milestone in conversational AI, demonstrating the potential for AI
systems to engage in human-like conversations. However, ongoing research,
ethical considerations, and improvements are crucial to unlocking the full
potential of ChatGPT and ensuring its responsible and beneficial integration
into various domains.
Additional Information from ChatGPT
Practical
Applications: Discuss some practical applications
of ChatGPT beyond general conversation, such as customer support, virtual
assistants, language translation, content generation, or creative writing.
Highlight specific industries or domains where ChatGPT can be beneficial and
provide examples of real-world use cases.
User
Experience and Feedback: Discuss the importance of
user experience in interacting with ChatGPT. Include considerations such as
response quality, clarity, coherence, and understanding user intent. Also,
mention the significance of gathering user feedback to improve the system and
address any limitations or biases.
Comparative
Analysis: Compare ChatGPT with other conversational
AI models or systems, highlighting its unique features, advantages, and
potential drawbacks in relation to similar technologies. This can provide a
broader context and perspective on the strengths and limitations of ChatGPT.
Future Directions: Offer insights into potential future developments and advancements in ChatGPT or conversational AI as a whole. Discuss ongoing research, challenges, and possibilities for addressing limitations, improving performance, and enhancing the ethical considerations associated with AI-powered conversational systems. [9]
References
- Open AI. (2021, June 18). https://openai.com/
- DrHemanMohabeer. (2020, May 16). The subtle art of chatbot development- Client requirements versus client expectations. Data Science Central. https://www.datasciencecentral.com/the-subtle-art-of-chatbot-development-client-requirements-versus/
- Majid, U. (2022, December 17). How chat GPT utilizes the advancements in artificial intelligence to create a revolutionary language model. Pegasus One. https://www.pegasusone.com/how-chat-gpt-utilizes-the-advancements-in-artificial-intelligence-to-create-a-revolutionary-language-model/
- Gagandeep. (2023, January 4). ChatGPT by OpenAI – An AI chatbot. Copperpod IP. https://www.copperpodip.com/post/chatgpt-by-openai-an-ai-chatbot
- Brown, T. B., et al. (2020). Language models are few-shot learners. arXiv preprint arXiv:2005.14165.
- Radford, A., et al. (2019). Language models are unsupervised multitask learners. OpenAI Blog.
- Holtzman, A., et al. (2019). The curious case of neural text degeneration. arXiv preprint arXiv:1904.09751.
- Bender, E. M., et al. (2021). On the dangers of stochastic parrots: Can language models be too big? Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency.
CrossRef - Jurafsky, D., & Martin, J. H. (2019). Speech and Language Processing. Pearson Education.

This work is licensed under a Creative Commons Attribution 4.0 International License.